
✅Pandas — Biến dữ liệu thô thành quyết định thông minh
Bạn có dữ liệu — nhưng vấn đề là làm gì với nó. Pandas là thư viện Python mạnh mẽ để làm sạch, phân tích và chuyển đổi dữ liệu nhanh chóng — từ những file CSV nhỏ tới khối dữ liệu lớn chuẩn bị cho mô hình ML hay báo cáo kinh doanh. Dễ học, giàu tính năng và tích hợp tuyệt vời với hệ sinh thái Python (NumPy, Matplotlib, scikit-learn…), Pandas giúp bạn đi từ dữ liệu đến giá trị trong thời gian ngắn.
✅Vì sao chọn Pandas?
-
Dễ dùng: API trực quan (
DataFrame,Series) cho thao tác dạng bảng giống Excel nhưng linh hoạt hơn. -
Nhanh: thao tác vectorized, groupby, join, pivot tối ưu cho phân tích.
-
Linh hoạt: đọc/ghi nhiều định dạng (CSV, Excel, SQL, JSON, Parquet…).
-
Hệ sinh thái: hoạt động mượt với matplotlib, seaborn, scikit-learn, Dask/Modin khi cần scale.
-
Tiết kiệm thời gian: thay vì code xử lý từng dòng, Pandas làm việc cốt lõi với toàn bộ cột/khối dữ liệu.
✅Tính năng chính (tóm tắt)
-
Cấu trúc dữ liệu
DataFrame&Series. -
Đọc/ghi dữ liệu:
read_csv,read_excel,to_csv,to_parquet… -
Lọc, chọn, sắp xếp, gán cột mới (
loc,iloc, boolean indexing). -
Grouping & aggregation (
groupby,agg). -
Join/merge dữ liệu (
merge,concat). -
Pivot, pivot_table, crosstab.
-
Xử lý missing (
fillna,dropna,interpolate). -
Chuyển đổi kiểu dữ liệu, parse thời gian (
to_datetime). -
Window functions, rolling, expanding.
-
Time series indexing & resampling.
-
Hiệu năng:
categoricaldtype, chunked reading, vectorized ops.
✅Cách cài đặt nhanh
Hướng dẫn sử dụng chi tiết (mã mẫu & giải thích)
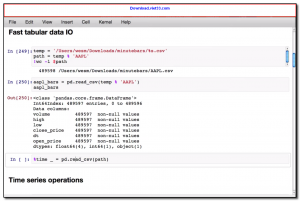
1) Khởi tạo & đọc dữ liệu
Giải thích: parse_dates tự động chuyển cột về datetime, rất tiện cho phân tích thời gian.
2) Xem nhanh & hiểu dữ liệu
3) Lọc, chọn cột và truy cập hàng
4) GroupBy & aggregate — báo cáo nhanh
Giải thích: agg với tên cột mới giúp tạo báo cáo gọn, rõ.
5) Merge / Join / Concat
Giải thích: how="left" giữ tất cả khách hàng, thêm đơn hàng nếu có — giống SQL JOIN.
6) Pivot / Crosstab (bảng chéo)
7) Xử lý missing
8) Time series & resample
9) Window functions & Rolling
10) Chuyển đổi kiểu, tối ưu bộ nhớ
Giải thích: category tiết kiệm bộ nhớ và tăng tốc groupby cho cột có ít giá trị khác nhau.
11) Đọc file lớn (chunked)
12) Xuất kết quả
Ví dụ thực chiến — Phân tích doanh thu nhanh (tóm tắt)
-
Đọc
orders.csv(cột: order_id, order_date, customer_id, product, qty, price, region). -
Tạo
revenue = qty * price. -
Resample theo tháng:
monthly_rev = df.resample("M").revenue.sum(). -
Tìm top 5 sản phẩm theo doanh thu:
df.groupby("product").revenue.sum().nlargest(5). -
Lưu report & vẽ biểu đồ (matplotlib):
monthly_rev.plot().
Mẹo & best practices
-
Tránh vòng
fortrên hàng — dùng vectorized operations. -
Sử dụng
assign()vàpipe()để viết pipeline rõ ràng. -
Khi dữ liệu lớn, dùng
chunksizehoặc công cụ scale như Dask/Modin. -
Chuyển cột dạng text thành
categorynếu số giá trị hạn chế. -
Kiểm tra
dtypesớm (nhất là ngày tháng, số) để tránh lỗi khi group/merge. -
Viết unit tests cho các bước chuyển đổi dữ liệu quan trọng.
Kết luận
Pandas không chỉ là một công cụ — nó là cầu nối giữa dữ liệu thô và quyết định có giá trị. Dù bạn là nhà phân tích, data scientist hay lập trình viên, Pandas giúp bạn xử lý dữ liệu nhanh hơn, gọn gàng hơn và chuyên nghiệp hơn. Cài đặt ngay, mở file của bạn và biến những con số rời rạc thành câu chuyện kinh doanh có trọng lượng.
 Download AutoIt – phần mềm và ngôn ngữ kịch bản (script)
9120 Lượt tải
Download AutoIt – phần mềm và ngôn ngữ kịch bản (script)
9120 Lượt tải
 Download CONSTRUCT 2– PHẦN MỀM LÀM GAME 2D KHÔNG CẦN BIẾT LẬP TRÌNH
9025 Lượt tải
Download CONSTRUCT 2– PHẦN MỀM LÀM GAME 2D KHÔNG CẦN BIẾT LẬP TRÌNH
9025 Lượt tải
 Download AEdiX Suite– Bộ Công Cụ Chỉnh Sửa Hex Mạnh Mẽ
9828 Lượt tải
Download AEdiX Suite– Bộ Công Cụ Chỉnh Sửa Hex Mạnh Mẽ
9828 Lượt tải
 Download UltraEdit– Trình Soạn Thảo Văn Bản & Mã Nguồn Mạnh Mẽ
9497 Lượt tải
Download UltraEdit– Trình Soạn Thảo Văn Bản & Mã Nguồn Mạnh Mẽ
9497 Lượt tải
 Download SciTE– Trình Soạn Thảo Mã Nguồn Nhẹ
10781 Lượt tải
Download SciTE– Trình Soạn Thảo Mã Nguồn Nhẹ
10781 Lượt tải



